Augmenting Agile with Formal Methods
I really like the c2 wiki as a historical artifact: a lot of big names in Agile and Extreme Programming argued with each other there.1 One thing they did was the Extreme Programming Challenge, where people tried to test the limits of these approaches. They’d find edge problems (designing databases, remote teams, etc) and see if Agile/XP still worked in that context. In almost every case they quickly decided that yes, it works just fine.
The exception is Challenge Fourteen. Tom Cargill asked people to write tests for concurrency code. Unlike the rest of the challenges, he had a code sample.
class BoundedBuffer {
synchronized
void put(Object x) throws InterruptedException {
while( occupied == buffer.length )
wait();
notify();
++occupied;
putAt %= buffer.length;
buffer[putAt++] = x;
}
synchronized
Object take() throws InterruptedException {
while( occupied == 0 )
wait();
notify();
--occupied;
takeAt %= buffer.length;
return buffer[takeAt++];
}
private Object[] buffer = new Object[4];
private int putAt, takeAt, occupied;
}
Cargill said this has a bug but didn’t tell people what it was. As he put it:
The concrete challenge is to create a test that exposes the bug.
The abstract challenge is to explain how concurrent code can be refactored at an extreme rate.
To be able to refactor concurrent code “at an extreme rate”, you have to be able to validate it at an extreme rate. Participants would have to find the bug on their own.
Nobody could do it. Don Wells even said that Cargill was mistaken: the code was just fine! After a few weeks2 Cargill revealed the bug and asked if anybody could write a test knowing now what to specifically look for. A few weeks after that Wells finally managed it: if he took 11 threads and ran one specific test 250 times, there was a good (but not certain!) chance one of those runs would exhibit the bug. He claimed finding the right test took him about 16 hours, or “two days on an actual project”, and that this proved concurrent code wasn’t a problem for XP. Everybody else disagreed.
Concurrency is evil. Synchronous algorithms have a single well-defined output for a given input. Concurrent algorithms have a set of possible outputs depending on the order of events. There are n! ways to order n unique, independent events. Assuming each thread runs exactly once, that’s almost 40,000,000 different behaviors. Some of these are impossible, and some are permutations of other behaviors, but even so you’re looking at hundreds or thousands of distinct behaviors to test. And you have to test them all, as even one broken behavior is enough to crash production.
It doesn’t help that testing specific behaviors is notoriously difficult. Fortunately, we have much a better tool for studying concurrency: formal methods. By creating a mathematical description of the system, we can explore its properties in abstract. Checking a few thousand behaviors of a design is much easier than setting up a few thousand finely-tuned test cases.
I wanted to see how effective formal methods would be here. I decided to time how quickly I could identify the bug using a specification. To more accurately capture the challenge I did not look at the solution beforehand: as with the Agilists, my process would have to lead me to the bug.
My spec language of choice was TLA+. Not only is it extremely good at modeling concurrency, but it has a DSL, PlusCal, that is almost perfect for representing sequential processes. I wrote a spec and then used the TLC model-checker to evaluate all of the reachable states. I’ve talked about TLA+ a bunch before, but if this is the first you’re hearing about it, I have a gentler intro here.
Writing the Spec
I spent about ten minutes looking at the snippet, trying to figure out what it was doing. Java isn’t my strong suite and I needed to check the semantics of some keywords.
synchronizedmeans the methods are atomic. The Java scheduler will run the entire body of the method before switching to another scheduler.wait()puts a thread to sleep. Simple enough.notify()tells the scheduler to check if there are any sleeping threads and, if there are, wake up one of them.
notify() just screams “weird concurrency bugs” to me so I decided to first check if the scheduling logic was safe, and then fill out the buffer logic later. I spent another 10 minutes writing the spec.
---- MODULE xp ----
EXTENDS Integers, TLC, Sequences, FiniteSets
CONSTANTS BuffLen, Threads
ASSUME BuffLen \in Nat
ASSUME Cardinality(Threads) >= 2
(* --algorithm xp
variables
Getters \in (SUBSET Threads) \ {{}, Threads};
Putters = Threads \ Getters;
Instead of making Getters and Putters constants I decide to make the set of threads constant and define the get and put threads as subsets. That way I don’t have to specifically check something like “10 puts, 1 get”, I can just say “11 threads” and TLC will check all possible partitions.
The only sets I rule out are “no gets” and “no puts”. Both of those will trivially deadlock so I’m not interested in them.
buffer = <<>>;
put_at = 1;
get_at = 1;
awake = [t \in Threads |-> TRUE];
occupied = 0;
Even though we’re not starting with buffer logic, I put the variables in anyway because why not. buffer is an empty sequence, awake maps each thread to a boolean value, kind of like a python dict.
define
IsFull == occupied = BuffLen
IsEmpty == occupied = 0
SleepingThreads == {t \in Threads: ~awake[t]}
end define;
Helper operators. SleepingThreads is a simple filter on sets. In TLA+, ~ means “not”.
macro notify() begin
if SleepingThreads /= {} then
with t \in SleepingThreads do
awake[t] := TRUE;
end with;
end if;
end macro;
with nondeterministically pulls an arbitrary element from SleepingThreads. Since TLC is an exhaustive checker, it will verify all possible selections. So if something calls notify() and there are three sleeping threads, TLC will split into three new timelines, one for each element, and check them all. If in one of those timelines we immediately call notify() again TLC will split that into two more timelines.
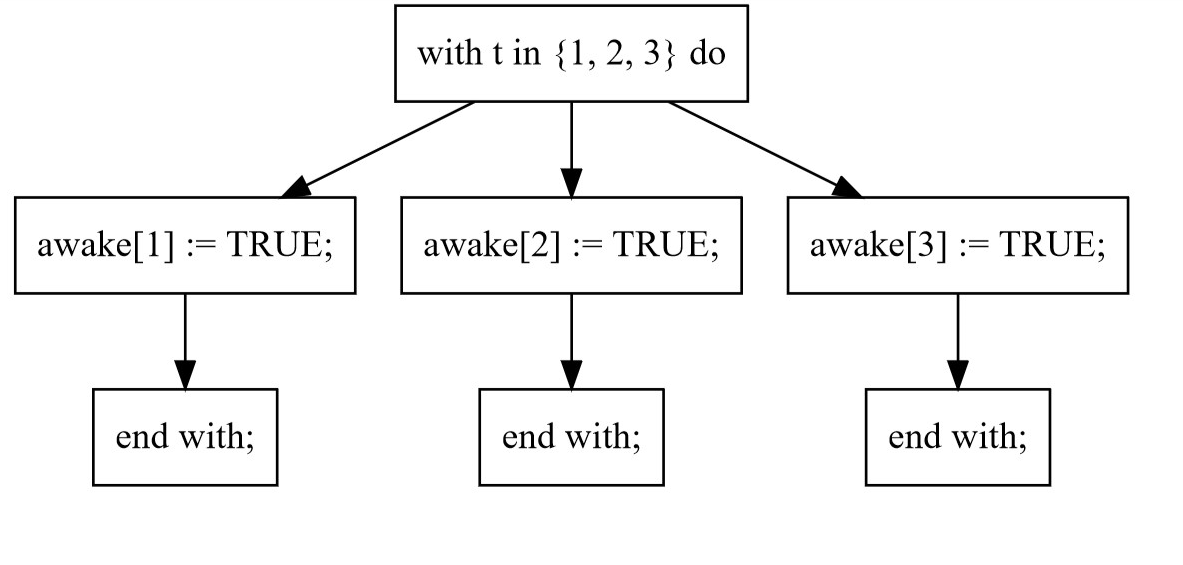
`with` causes the model checker to branch timelines.
process get \in Getters
begin Get:
await awake[self];
if IsEmpty then
awake[self] := FALSE;
else
notify();
occupied := occupied - 1;
end if;
goto Get;
end process;
process put \in Putters
begin Put:
await awake[self];
if IsFull then
awake[self] := FALSE;
else
notify();
occupied := occupied + 1;
end if;
goto Put;
end process;
end algorithm; *)
====
get and put are pretty straightforward translations of the Java code. Each has a single label, which represents the unit of atomicity. Since each process has only one label, TLC will evaluate the entire body before switching to another process. As with with, the choice of next process to run is nondeterministic, so after evaluating one process it will create another timeline for each other awake process. This is all on top of the with forks, so the state space balloons extremely quickly.
Running the Model
Cargill hardcoded the buffer length to 4, but I decided to generalize it. Before getting to more complex properties, I had TLC check for deadlocks, undefined operations, and type errors. I first ran TLC with BuffLen <- 2, Threads <- 1..2. That passed. I also ran a model with four threads and eight threads. 4 threads passed, too. But when we had 8 threads, we get a deadlock:
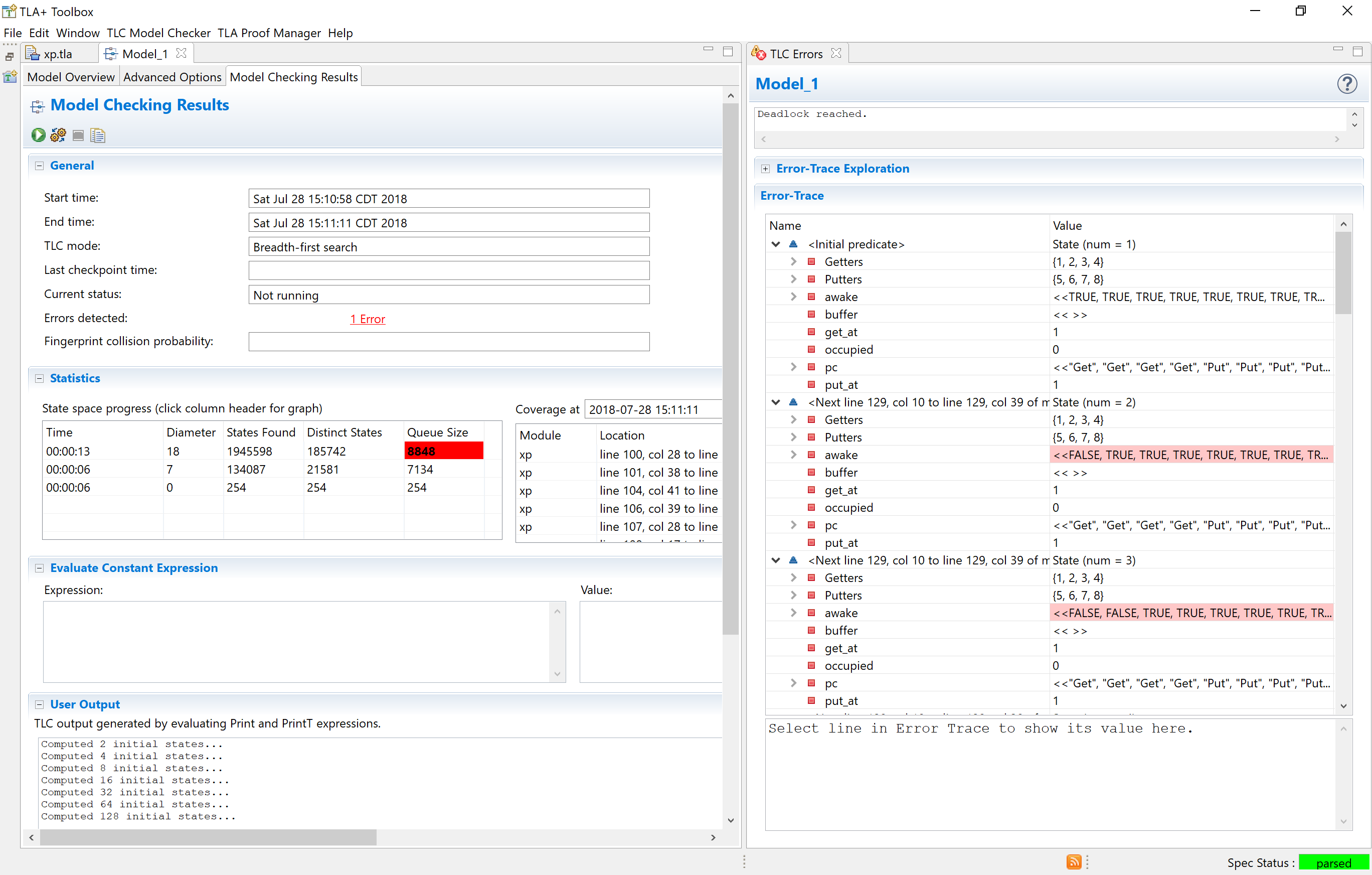
It takes some experience to read an error trace, so to make it easier on y’all I reproduced the deadlock with BuffLen = 1 and three threads, then cleaned up the output. The last index of await is the put thread, the other two are gets. If a thread did not change its awake value, then I lowercased it.
1: \* Initial State
awake = <<TRUE, TRUE, TRUE>>
Getters = {1, 2}
Putters = {3}
occupied = 0
2: \* lowercase means it did not change here
awake = <<FALSE, true, true>>
occupied = 0
3:
awake = <<false, FALSE, true>>
occupied = 0
4:
awake = <<false, TRUE, true>>
occupied = 1
5:
awake = <<false, true, FALSE>>
occupied = 1
6: \* This is where the bug happens
awake = <<TRUE, true, false>>
occupied = 0
7:
awake = <<FALSE, true, false>>
occupied = 0
8: \* deadlock!
awake = <<false, FALSE, false>>
occupied = 0
The problem is step 6: the get thread calls notify, but instead of waking the put thread, wakes the other get thread. This leads us to a state where the buffer is empty but all of the put threads are asleep, so the get threads can’t wake them up. This is the exact same error Cargill had!
Elapsed time: 31 minutes.
We can go further than that, though. Well’s solution used 11 threads. What’s the minimum number of threads that can deadlock? By playing around with BuffLen and Threads, I found out that the system will never deadlock as long as Threads <= 2*BuffLen. So for a buffer length of four, you need 9 threads to have a deadlock. Wells needed an extra two (and multiple runs) to because the state space is so big, which isn’t as much a problem for our model checker.
Now let’s also figure out the solution. Someone mentioned that instead of notify(), you really want to use notifyAll(), which wakes up every thread. Does that fix it?
+macro notify_all() begin
+ awake := [t \in Threads |-> TRUE];
+end macro;
process get \in Getters
begin Get:
await awake[self];
if IsEmpty then
awake[self] := FALSE;
else
- notify();
+ notify_all();
occupied := occupied - 1;
end if;
goto Get;
end process;
process put \in Putters
begin Put:
await awake[self];
if IsFull then
awake[self] := FALSE;
else
- notify();
+ notify_all();
occupied := occupied + 1;
end if;
goto Put;
end process;
end algorithm; *)
On rerunning the models, we see the system no longer deadlocks.
Is it worth it?
People usually dismiss formal methods as taking too much time for too little payoff. Writing this spec and finding the error took half an hour versus the 16 hours it took Wells to find it via unit tests. But 16 hours is too optimistic for the Agile approach. If you read the challenge discussion, you see that:
- Several people wrote extensive tests suites and couldn’t find the bug. Ron Jeffries did a code review and couldn’t find the bug. Before Cargill gave the solution, Wells claimed his unit tests showed there wasn’t a bug. It’s incredibly likely this would have gone into production.
- Jeffries said he didn’t understand the bug, even after reading the step-by-step explanation. Even if somebody was trying to figure out why their system deadlocks, they’d have a tough time narrowing it down to this. God knows I’ve had issues finding much more obvious bugs in code.
Once he knew what the bug was, it still took Wells several hours to write a unit test that caught it. Even then, the test was incredibly fine-tuned and had to be run 250 times in a row to usually catch the bug. If he modified the function and the unit test starts passing, there’s no way to know whether he actually fixed the bug or just moved it outside of the test’s calibration.
Case in point: Wells identified the bug happens because “take threads are not specifically limited to put threads as they should be.” Changing the getters to only wake up putters makes all of his tests pass, but the code is still broken (put threads can wake other put threads). It just requires a slightly different configuration and several more steps, so his tests don’t find it.
On top of it all, Wells had each iteration timeout after 5 seconds. Worst case scenario, that adds about 20 minutes to your test suite per unit test. That’s almost as long as I spent on the entire problem.
The difference between writing TLA+ and just writing unit tests isn’t half an hour versus sixteen hours, it’s half an hour versus “Two weeks to realize there’s a bug, a week to find the bug, three days to understand the bug, sixteen hours to write the test, twenty minutes to run the test, and you don’t know if your fix really works.”
Caveats
Wouldn’t be my kinda post if I didn’t talk about limitations.
The big one is that the TLA+ spec isn’t code. It exists independently of the Java and there’s currently no tools that automatically relate them. Relating code and specs is a hard problem in general and most of the specification languages that support it are either high-effort, very experimental, or targetted at narrow domains.
In practice, how big a problem this is depends on what you wanted. There’s very roughly three issues people have with “nonexecutable” specs.
- “You still have to write the code yourself, so making a spec is a waste of time.” I think this is a pretty bad reason: we already demonstrated that it can save a lot of time and pain.
- “The code and the spec might diverge over time.” No easy answer here. A really nice thing about tests/types/contracts is they mostly stay in sync with the code, but you don’t get that guarantee with TLA+, which is a problem.
- “You might make a mistake translating the spec to code.” This one is really interesting. I’ll admit I have made mistakes translating specs before, leading to bugs in the implemented system. You still need to rigorously test and review the code you write; specs can’t really help you here. At the same time, you have that problem with any code you write. If you write it without a spec, though, you don’t know whether the code is buggy because the implementation is wrong or because the fundamental design is wrong.
Additionally, TLA+ specs can take a long time to run. For a small model like this one it isn’t too bad, but you tried, say, BuffLen <- 10 and Threads <- 21, it will take a very long time to finish. There’s some symmetry tricks you can exploit to reduce the state space, and you can parallelize checking safety invariants, but you’re still not going to be able to run this as part of your CI.
Finally, the comparison here isn’t completely accurate, because I got lucky with the bug. Since I first wrote and verified the locking code, I didn’t need to write the rest of the logic. If the bug was something about the data in the buffer itself I would have had to flesh that stuff out. By contrast, the Agilists were also trying to test that the buffer data was also valid. Extending the spec would take a little more time, making the relative effort ratio a little less extreme.3
Ultimately, though, I’m fine with these limitations. I’m not suggesting formal methods replaces heavy refactoring, pairing, testing, etc, but that it augments it. Specifications give us a means of thinking quickly and deeply about complex systems and finding flaws in our designs. It helps us build higher-quality systems faster and cheaper. If that isn’t Agile I don’t know what is.
If this stuff interests you, I wrote a free tutorial on TLA+ and am currently writing a full book due out in December. I also do workshops and consulting for interested companies. I think TLA+ (and FM in general) is an incredibly valuable tool that’s far more widely applicable than people suspect.
Thanks to Jay Parlar and Michael Feathers for feedback.
- Extreme Programming was a programming discipline emphasizing short iterations, test-driven development, pair programming, and customer involvement. Most of the ideas (and XP pioneers) went on to form the core of modern Agile software development. There are some differences, but I’m comfortable equating the two for this essay. [return]
- Working out timelines on c2 is really hard. I’m basing this off comments across all of the threads. [return]
- One important caveat: after seeing the error stack I thought it looked familiar, and then realized that someone else did this problem in TLA+ too. I didn’t remember about the article until after I finished the exercise but there’s a chance it could have unconsciously affected how fast I solved it. [return]