Why Do Interviewers Ask Linked List Questions?
A couple years back I gave a talk on researching software history, using “linked list interview questions” as an example topic. Since referring people to a video is less accessible than just writing a blog post, I’ve reproduced the question here.
So why do interviewers like to ask linked list questions? If you ask people, you usually get one of two answers:
- “It tests CS fundamentals.”
- “It tests reasoning through a new problem.”
These answers are contradictory: if you want to know if someone knows CS fundamentals, you don’t want to give them a problem they can trick their way through, and if you want to test reasoning ability, you don’t want to give a problem that they’ve already seen in CS. Two contradictory answers tells me there’s some history involved. My guess is that originally people asked LL questions for a very good reason, and then over time forgot the reason and came up with post-hoc justifications. I’ve seen this happen before. So when did people start asking LL questions, and what were their reasons?
Pinning the when
First step is to figure out when people started asking the question. The first thing I always try is interviewing. People record only a fraction in writing of what they care about, so memories are the richest source of cultural context. Really, the biggest challenge to interviewing is finding people. I assumed LL questions were first asked in the 90’s. There’s enough people from that time on Twitter and I’m lucky enough to have a good Twitter following, so I asked directly:
Did you do a programming interview or interview others in the early 90's? If so, what were the questions like?
— Inactive; Bluesky is @hillelwayne(dot)com (@hillelogram) May 29, 2019
I then followed up in DMs. What I heard surprised me: to them, linked list questions were done “because they were always done”. I had to go earlier, so set my new target dates on 1970 and 1980.
The earlier we go, the harder it is to find people. If you graduated college in 1970 and immediately got your first programming job, then you’d be 73 now. There’s a good chance you’re totally disconnected from the programming scene. Fortunately, the Chicago ACM chapter skews older, and plenty of the attendees are around that age. Based on their memories, LL questions started appearing around the late 70’s to mid 80’s.
They couldn’t tell me the why, though: people’s memories are gonna be fuzzy about interview questions from forty years ago. Eyewitness accounts are great but only took me so far.
Next comes building out the context that of time: what people were trying to do and why. That means examining the cultural artifacts, or the primary sources.
Primary Sources
Quick sidebar on evidence. There’s two broad classes of historical evidence:
- Primary Sources: Information directly connected to the topic at hand. Examples: Reddit convos. Code samples. A Kubernetes tutorial. Interviews with people who were there.
- Secondary Sources: Information produced by other people analyzing primary sources. Examples: A HOPL paper. Books about the history of software. This post.1
Secondary sources are easier for most people to consume. Primary sources are messy, contradictory, and incomplete, while secondary sources can be cleaned up and presented accessibly. But we want the messy and contradictory information. Secondary sources by necessity must oversimplify things and lose nuance.2 Secondary sources are great for learning history but bad for doing history. We need to use primary sources.
What
Some primary sources are more accessible than others. Something like the Computer History Museum would have been a huge help in researching this, but I wasn’t gonna fly across the country to read about linked lists. And some primary sources are more useful than others. If I could get my hands on a 1980 interviewing booklet, that would end my search immediately. In practice this is unlikely, but it’s still worth sweeping for black swans on the off chance you find one. In this case, no luck, nor did a skim of the ACM Digital Library turn up anything interesting.
Next up: finding records of people talking about the job process and see what they say. Most of these discussions happened in person, but I know at least two places they might have been archived. Place one: Bulletin Board Systems, which first appeared around 1978. Place two: Usenet, which comes up after 1980. I expected to get more information from Usenet, being bigger and better preserved, but BBSes are appealing since they start a little earlier. Neither of these would be a perfect representation of the past computing world, much like how Hacker News isn’t a good representation of the present.3 That’s primary sources for ya!
I couldn’t find any BBS archives; Usenet it is! The Internet Archive has a dump of 2,000 net.jobs posts between 82 and 86. Nobody talked about the interviewing process, though, permanently closing that line of investigation.
With that, any answers I come up with are going to be based on me interpreting primary sources. I’ve found the best way to study this kind of history is to use a form of the scientific method: gather the evidence, make a hypothesis, and then predict other historical evidence based on that hypothesis. Are there any patterns to the job postings?
There were two, in fact. One: a whole lot of people are hiring for Unix and C programmers. 1 in 6 posts were for C and almost half of them mention Unix. This is a little more impressive when you realize 1) this was all jobs, not just “low-level” ones, and 2) Unix was competing with many other OSes at the time. Two, a whole lot of people don’t care about academic credentials. Only about 50% of them asked for academic experience, and many of those were fine with an EE degree! That threw a wrench in the “it’s about CS fundamentals!” hypothesis.
Then I noticed something interesting: the second most popular language.
It was Pascal.
Rampant Speculation
Let’s zoom out a bit. Imagine you have a linked list and you need to append a new value to the end. How do you do it? It depends on the language.
- FORTRAN-77: You don’t have any dynamic memory or data structures, so this is impossible in the first place.
- Maclisp:
(list . 1) - Smalltalk-80:
list addLast: (Entry for: 1) - C: Take your hand-rolled custom linked list data structure, walk through it until you reach the last node, allocate memory for a new node, and set the last element’s
nextto that new node. - Pascal: same
C and Pascal were the most popular languages, and they were the only “mainstream” languages that required you to implement linked list algorithms by hand.4 You were working with linked list algorithms, day in, day out. So “reverse this linked list” isn’t a test of algorithm knowledge or “thinking on your feet”. It’s a test of if you’ve programmed C.
(Or Pascal.)
What’s especially interesting about purpose is it’s the complete opposite of the purposes we think of today. Companies weren’t testing for theoretical CS knowledge, they were testing for practical experience with pointers.5 The question shouldn’t be something that everybody with academic CS knowledge would get, otherwise it wouldn’t test for experience. Similarly, you shouldn’t be able to “reason through it” in ten minutes. A question should be something that’s easy if you know C and impossible otherwise. LL questions come pretty close to that!
Predictions
So I have my hypothesis. What does it predict? The one I came up with was “C and Pascal programmers should talk about pointer manipulation a lot more often than other programmers.” You’d expect that the more people discuss pointers, the more direct memory manipulation matters to them. The Archive has 1980’s Usenet dumps of a bunch of different languages. I picked five languages- LISP, Prolog, Smalltalk, Pascal, and C- and got to work.6
The naive thing to do would be to just grep them all for “pointer”. That got me this:
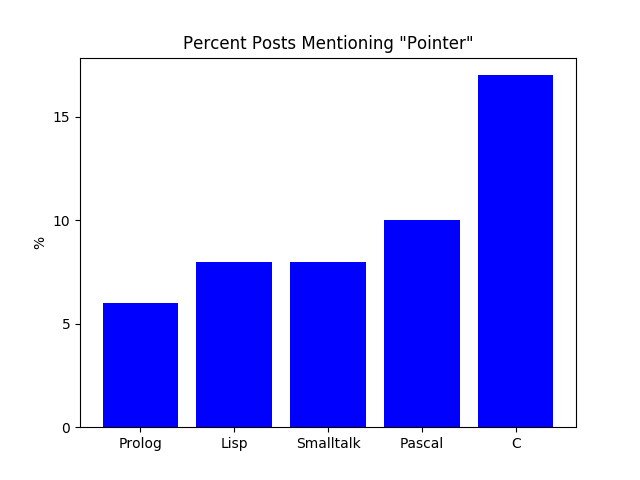
6% of Prolog posts and 8% of Smalltalk and Lisp posts mention pointers, while 10% of Pascal and 17% of C posts do. That’s a pretty strong signal.
…Oh wait, “pointer” is also an English word. I can’t just rely on automated tools to crunch data.7 If I really wanted to get something accurate, I’d have to go through the posts manually and weed out the false positives.
There were 1,917 posts about pointers.
Two hours later, I had a new graph:
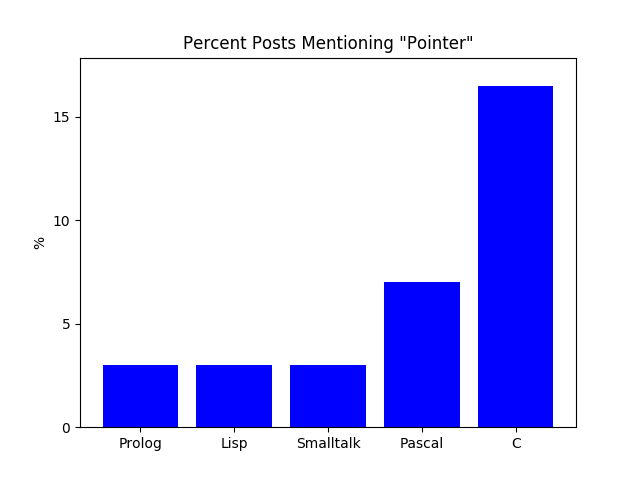
Only 3% of Prolog, Smalltalk, and Lisp posts talked about pointers as memory-manipulation, which suggests to me it really wasn’t that important. Whereas Pascal drops from 10% to 7% and C drops from 17% to 16.5%.
So now we have:
- Companies were hiring tons of C and (to a lesser extent) Pascal programmers
- Companies cared more about professional experience than academic credentials
- C and Pascal place a lot more emphasis on memory manipulation than other languages
- C and Pascal programmers had to implement linked list algorithms themselves, while other languages provided libraries.
This isn’t definitive evidence that LL interview questions were an experience shibboleth. Then again, nothing can be definitive evidence, short of a time machine or an incredibly lucky find. It’s enough for me, though.
Why do we still ask them?
So one last question: why do we still ask LL questions? Many of us don’t work in low-level languages anymore, so we shouldn’t be expected to have manipulated LLs before. Why does the question still persist absent the context?
This is a good place to draw the Great Man theory of history out of the dumpster: the right person in the right place at the right time can permanent change the course of history. In this story, there are two persons. The first is Joel Spolsky’s The Guerilla Guide to Interviewing. He claimed that pointer questions in general, and linked lists in particular, are a fundamental test of your “abstract thinking”:
Pointers require a complex form of doubly-indirected thinking that some people just can’t do, and it’s pretty crucial to good programming. A lot of the “script jocks” who started programming by copying JavaScript snippets into their web pages and went on to learn Perl never learned about pointers, and they can never quite produce code of the quality you need.
That’s the source of all these famous interview questions you hear about, like “reversing a linked list” or “detect loops in a tree structure.”
This looks like counterevidence to my hypothesis. Spolsky wrote that in 2006, when he was running Fog Creek.8 Fog Creek used a mix of VBA and C#, neither of which require you to write your own LL algorithms. However, he started his career at Microsoft, working there from 1991-1995. At the time Microsoft made 40% of their revenue from operating systems… exactly the kind of company that would find LL questions relevant.
I suspect The Guerilla Guide played a major role in spreading LL questions. At the time there were few public resources on running tech interviews. The Guerilla Guide provided a good launching point for building your process. It didn’t hurt that Spolsky was a minor tech celebrity. Linked list questions are Joel Spolsky Approved™, so why not use them?
That really took off in 2008, when Gayle Laakmann McDowell released Cracking the Coding Interview. While aimed helping interviewees, it was also a huge boon to interviewers, who now had a large pool of thorough questions to choose from. McDowell based CCI on her experiences at Apple, Microsoft, and Google- again, all places where LL algorithms are directly relevant to their use cases. I’m not surprised she placed an outsized focus on them in her book, and I’m not surprised that many companies started asking them regardless of relevancy.
Ironically, this also made LL questions useless for their original purpose. You can’t test if someone is good at C by asking them to reverse a linked list. They might know how to reverse linked lists because they needed to learn to pass interviews!
Postscript
So, to summarize the theory: in the early 80’s, C programmers were in high demand. Interviewers used questions that specifically tested your experience with C, which meant problems involving lots of pointer manipulation. This ingrained LL questions as a cultural institution in many places, especially places doing lots of low-level work, like Microsoft and Google. From there, it was exported to the wider software world, and lacking the original context, people assumed it was about “testing CS fundamentals” or “quick thinking”.
This, of course, could all be completely wrong. History is like that, even people with the same sources can reasonably come to different conclusions. Nonetheless, I feel like this question perfectly captures why I love studying history. Even things as mundane as the interview questions we ask can have rich stories underneath. And it’s accessible, too: I didn’t need any special tools besides the internet and a lot of time. The only thing that cost me money was my Digital Library subscription.
If you enjoyed this, I want to encourage you to do this, too! Find something that always bugged you about software and look into the history. And share what you learn! We’re all enriched when people share the histories in even the simplest things.
Thanks to Alex Koppel for feedback. If you liked this post, why not join my newsletter? I send weekly essays and first drafts of blog posts. Subscribe here or read the archives here.
- Whether a source is primary or secondary depends on the context. A programming textbook is a secondary source about the history of computer science, but a primary source about the history of how we taught computer science. [return]
- Also, the producers of the secondary source have biases and agendas. That’s fine, everybody does, it’s impossible to not have biases. But I’d rather filter sources through my own biases than through another person and me. (There’s actually a lot more nuance here, and there are many cases where reading secondary sources is important. But this tangent has already gone way off track.) [return]
- While writing this I realized I missed a third potential source: early copies of Byte Magazine. The Internet Archive digitized copies of the entire run; maybe one of them discusses interviewing? I haven’t checked. [return]
- To be clear, this doesn’t mean that only C and Pascal programmers knew about linked lists and their properties. Data structures have been part of CS since forever. I’m claiming that only C and Pascal programmers needed to regularly implement LL algorithms, since contemporary languages provided more abstractions. [return]
- This gives us another prediction! If companies weren’t interested in “CS fundamentals” at the time then we’d expect to see the two other archetypical “CS fundamentals” questions, sorting algorithms and time complexity, develop as questions later. Ideally they’d appear at places where that knowledge was practically useful, but I can also see them appearing after people start misinterpreting LL questions as “CS Fundamentals” and decide that’s important to test. [return]
- While reviewing this post, my friend Alex Koppel suggested another idea: comparing how much the corresponding language manuals talk about memory manipulation. In retrospect, that’s a much better idea than trawling Usenet posts. I just didn’t think of it at the time, probably because I was already trawling Usenet to understand the job market. That’s a good research lesson: don’t over fixate on one primary source. [return]
- This has ruined software studies before! Most notoriously, this paper, where they grepped git commit messages for “fix” and accidentally included things like “add infix operators.” [return]
- Steve Yegge wrote something similar in 2004, based on his experiences at Amazon. I don’t think he was as influential as Spolsky, though: his other interview suggestions (bit twiddling, regexes) didn’t catch on. [return]